쿠팡 해킹 가설: 서버 인증 취약점과 내부자, 3,370만 계정 정보는 어떻게 빠져나갔나?
핵심 한 줄 요약
2025년 6월 24일부터 수개월간, 공격자는 쿠팡 서버의 인증 취약점을 악용해 정상 로그인 없이 3,370만 개 이상의 고객 계정에서 이름·이메일·전화번호·배송지 주소 등을 유출한 것으로 정부 조사에서 확인되었습니다.
먼저 분명히 합니다: 이 글은 ‘가설 분석’입니다
아래 분석은
현재까지 공개된 정부 발표, 언론 보도, 일반적인 웹/API 침해 시나리오를 바탕으로 정리한 합리적 가설입니다.
특히 이 글은
“핵심은 서버 인증 취약점 + 내부자 혹은 내부 지식 악용 가능성의 결합”이라는 가정을 중심으로 전개됩니다.
다만 다음 사항은 분명히 구분해야 합니다.
- 실제 사건의 전모는 수사 결과에 따라 달라질 수 있습니다.
- 내부자 개입 여부, 구체적 취약점 유형, 실제 악용 방식은 확정되지 않았을 수 있습니다.
- 따라서 이 글은 최종 판정문이 아니라, 실무적 교훈을 도출하기 위한 분석 문서입니다.
즉, 중요한 것은
“정확히 이 방식이었다”를 단정하는 것이 아니라,
왜 이런 유형의 대규모 유출이 장기간 탐지되지 않을 수 있었는가를 이해하는 데 있습니다.
1. 쿠팡 개인정보 유출 사건 개요
1.1 사건 요약
- 2025년 6월 24일경부터 해외 서버에서 쿠팡 고객정보 DB로 비정상 접근이 시작된 것으로 정부 조사에서 확인되었습니다.
- 공격자는 쿠팡 서버의 인증 취약점을 악용해 정상 로그인 절차 없이 3,000만 개 이상 계정을 대상으로 이름·이메일·전화번호·주소 등을 유출한 것으로 발표되었습니다.
- 쿠팡은 초기에 “4,500개 계정 노출”이라고 발표했지만, 이후 3,370만 계정 유출로 정정했습니다.
- 일부 언론에서는 초기 “유출” 대신 “노출” 표현 사용이 사고 규모를 축소해 보이게 했다는 비판도 제기했습니다.
1.2 유출 정보 범위
- 확인된 유출 항목
이름, 이메일 주소, 전화번호, 배송지 주소 등 - 특히 일부 사용자는 배송지 메모에
공동현관 비밀번호, 출입 방법 등 생활 정보를 적어둔 경우가 있어
2차 범죄 가능성까지 우려되었습니다. - 쿠팡은 결제정보·신용카드번호·로그인 정보는 유출되지 않았다고 밝혔지만,
- 정부는 이에 대해 “단정할 수 없다”며 추가 조사를 진행 중이라고 설명했습니다.
1.3 내부자 의혹
- 다수 보도에서 중국 국적 전 직원이 핵심 용의자로 언급되었습니다.
- 이미 해외로 출국한 상태라는 분석도 나왔습니다.
- 경찰은 협박성 이메일 정황 등을 포함해 수사 중인 것으로 알려졌습니다.
1.4 악성코드 및 외부 침입 흔적
현재까지의 보도에 따르면
악성코드나 전형적 외부 침입 흔적은 뚜렷하게 확인되지 않았습니다.
이 점은 매우 중요합니다.
왜냐하면 이번 사건이 전통적인 의미의
“포트 스캔 → 서버 침투 → 악성코드 설치”형 공격이 아니라,
- 인증·인가 설계 허점
- 내부용 기능 또는 신뢰 구조 악용
- 정상처럼 보이는 대량 조회
에 더 가까운 유형일 가능성을 보여 주기 때문입니다.
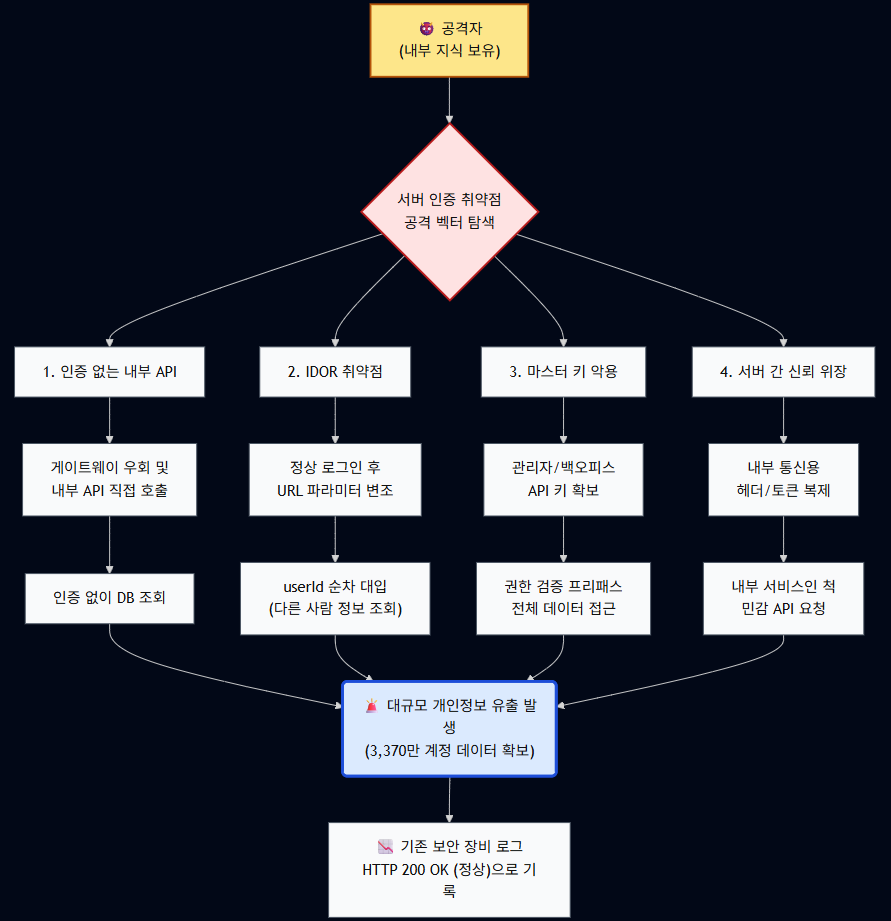
2. “서버 인증 취약점”이란 무엇인가
Broken Authentication / Broken Access Control 관점
정부가 언급한 “서버 인증 취약점”은
OWASP 기준으로 보면 Broken Authentication 또는 Broken Access Control 계열로 이해할 수 있습니다.
대표적인 시나리오는 다음과 같습니다.
2.1 인증이 빠진 내부용 API 외부 노출
예를 들어:
/internal/api/user-detail?userId=12345
같은 내부용 API가
라우팅, 프록시, 방화벽, 게이트웨이 설정 오류로 인해
외부에서 직접 호출 가능해지는 경우입니다.
이때 API 단에서 별도 인증·인가 검증이 없으면
userId만 바꿔도 다른 사용자의 정보가 반환될 수 있습니다.
2.2 IDOR (Insecure Direct Object Reference)
/api/user/{userId}/profile
처럼 객체 식별자를 직접 바꿔
다른 사용자의 정보에 접근할 수 있는 유형입니다.
겉으로는 정상 API처럼 보이지만,
실제로는 인가 검증 부재가 핵심 문제입니다.
2.3 마스터 계정 / 마스터 토큰 오남용
백오피스, 고객센터, 내부 운영 도구에서 쓰는
강한 권한의 API 키나 토큰이
- 회수되지 않았거나
- 범위가 과도하거나
- 외부에 유출되거나
- 내부 지식에 의해 재현될 경우
사실상 정상 로그인 없는 대량 조회가 가능해질 수 있습니다.
2.4 서버 간 신뢰 관계 위장
일부 시스템은
내부 서비스 간 호출을 전제로
간소한 헤더나 토큰만으로 신뢰를 부여합니다.
이 경우 공격자가
내부 서비스인 척 요청을 위장하면
민감 API를 호출할 수 있습니다.
3. 가설: 내부 지식 또는 내부 구조 이해를 가진 공격자의 흐름
이제 공개된 정황을 바탕으로
가장 설득력 있는 흐름을 가설 형태로 정리해 보겠습니다.
3.1 단계 1 — 내부 구조 및 취약 API 인지
공격자가
인증 시스템, 내부 API 구조, 백오피스 흐름, 마스터 키 관리 방식 등에 대한
깊은 이해를 가지고 있었다면,
일반 외부 공격자보다 훨씬 빠르게 취약 지점을 찾을 수 있었을 것입니다.
이 지점에서 내부자 본인 또는
내부 지식을 가진 외부 협력자 가능성이 함께 거론됩니다.
3.2 단계 2 — 해외 서버를 이용한 외부 접근 재현
공격자는 해외 VPS나 여러 중계 서버를 이용해
내부에서 사용되던 요청 패턴을 외부에서 재현했을 수 있습니다.
즉, 다음을 반복했을 가능성이 있습니다.
- 헤더 조합 실험
- 토큰/세션/파라미터 구조 재현
- 로그인 없이 응답이 나오는 엔드포인트 탐색
- 외부에서 호출 가능한 내부 API 확인
3.3 단계 3 — 인증 우회된 대량 조회 자동화
취약한 API가 확인되면
이후는 자동화 단계입니다.
- ID 범위를 순차 또는 랜덤으로 호출
- 응답 본문에서 이름, 이메일, 전화번호, 주소 추출
- 장기간에 걸쳐 낮은 속도로 수집
- 해외 인프라를 통해 분산 운영
이 구조라면
결과적으로 수천만 계정 규모의 정보가 수개월에 걸쳐 유출될 수 있습니다.
3.4 단계 4 — 왜 장기간 탐지되지 않았을까
이 부분이 이번 사건의 가장 중요한 교훈입니다.
탐지되지 않은 이유는
공격이 “시끄럽지 않았기” 때문일 수 있습니다.
- 모두 HTTP 200 OK 정상 응답
- 응답 구조도 정상 API처럼 보임
- 속도를 낮춰 정상 트래픽과 섞임
- 악성코드나 전통적 침입 흔적이 거의 없음
- 해외 IP라도 체계적 시나리오 탐지가 없으면 놓치기 쉬움
즉, 상태코드, 연결 성공 여부, 단순 트래픽 크기만 보면
이상해 보이지 않을 수 있습니다.
4. 이번 사건의 핵심: “요청/응답 본문 관제 부재”
이 사건이 특히 중요한 이유는
정상처럼 보이는 응답 속에서 데이터가 유출되었다는 점입니다.
요청/응답 본문에 어떤 데이터가 오고 갔는지 감시하지 않으면, HTTP 200 응답 속에서 수십만 건, 수백만 건의 개인정보가 빠져나가도 구조적으로 알아채기 어렵습니다.
이것이 이번 사건의 핵심입니다.
예를 들어 다음과 같은 신호는
상태코드만 봐서는 거의 보이지 않습니다.
- 응답 본문 안의 개인정보 필드가 과도하게 많음
- 동일 IP 또는 동일 세션/토큰에서 반복적으로 대량 조회
- 특정 API만 장기간 호출
- 정상 페이지처럼 보이지만 본문 내용은 사실상 데이터 덤프에 가까움
- 해외 IP + 대량 응답 + 사용자 식별 필드 조합
즉, 이번 사건은
요청/응답 본문(Body)을 실제로 보지 않으면 놓칠 수 있는 유형의 대표 사례로 볼 수 있습니다.
5. 근본 원인: 인증 설계 실패 + 모니터링 실패
5.1 인증·권한 설계 미흡
- 프런트 로그인만 확인하고
- 백엔드 API 단위의 권한 검증이 부족하거나
- 내부용 API를 과신하고
- 신뢰 경계를 좁게 설계하지 않았을 가능성
이런 구조는 결국
“로그인하지 않아도 데이터가 나오는 서버”를 만들 수 있습니다.
5.2 내부자/전직원 악용 방지 구조 부족
- 퇴사자 또는 전직원의 지식을 고려한 Zero Trust 부족
- 마스터 권한, 운영 API, 내부용 엔드포인트 관리 미흡
- 최소 권한, 즉시 회수, 사용 범위 제한 부족
즉, 문제는 단순히 외부 해커만이 아니라
내부 지식이 외부에서 재사용될 수 있다는 전제의 부재입니다.
5.3 대량 조회 탐지 체계 미흡
- 해외 IP + 반복 조회 + 대량 응답을 묶어 보는 시나리오 부재
- 낮은 속도로 길게 가는 공격을 탐지하는 정책 부족
- API 호출량 자체보다 응답 내용의 민감도를 보지 않은 구조
5.4 본문 기반 데이터 유출 탐지 부재
이번 사건의 가장 큰 교훈은 여기에 있습니다.
- 상태코드는 정상
- 세션은 겉으로 정상
- 연결도 정상
그런데 본문 안의 데이터가 비정상적으로 많이 나가고 있었다면,
그것을 봐야 했습니다.
즉, 이 사건은
네트워크 경계 보안만으로는 부족하고,
데이터 사용과 응답 자체를 감시하는 구조가 필요하다는 점을 보여 줍니다.
6. 그렇다면 무엇이 필요했을까?
일반적인 대응 원칙
여기서 중요한 것은
특정 벤더 제품보다 먼저 방어 원칙을 정리하는 것입니다.
6.1 API 단위 인증·인가 재검증
- 내부용 API 외부 노출 여부 점검
- IDOR 유형 테스트
- 마스터 토큰 사용 범위 최소화
- 서버 간 신뢰 모델 재설계
- 백오피스/API 권한 구조 분리
6.2 요청/응답 본문 기반 관제
- 개인정보 패턴 수, 민감 필드 밀도, 반복 조회 패턴 분석
- 응답 크기 자체보다 응답 내용의 의미를 해석
- 정상 200 응답 속의 대량 개인정보 반환 탐지
6.3 행위 기반 대량 조회 탐지
- 해외 IP + 동일 API 반복 호출
- 비정상 시간대 대량 조회
- 낮은 속도지만 장기간 지속되는 수집 패턴
- 신규 목적지/세션/토큰 기반 이상징후 결합
6.4 데이터 유출 관점의 다계층 방어
이런 유형은 단일 솔루션 하나로 해결하기 어렵습니다.
실전에서는 다음이 함께 필요합니다.
- API 게이트웨이/인증 계층
- 요청·응답 본문 모니터링
- DLP 관점의 민감정보 식별
- 행위 기반 XDR/상관 분석
- 사고 후 타임라인 재구성과 포렌식
즉, 핵심은
“정상처럼 보이는 데이터 유출”을 어떻게 비정상으로 보이게 만들 것인가입니다.
7. 본문 기반 대응의 예시로 볼 수 있는 구조
이 문제를 해결하는 접근 중 하나로는
요청/응답 본문을 분석하고, 행위 시나리오를 상관 분석하는 XDR 계열 구조를 들 수 있습니다.
예를 들어 PLURA-XDR 같은 접근은
다음과 같은 시나리오에서 의미를 가질 수 있습니다.
7.1 요청/응답 본문 분석으로 볼 수 있는 신호
- 응답 본문 내 개인정보 패턴 과다
- 동일 IP/토큰에서 반복되는 개인정보 응답
- 요청 본문에 userId/accountKey 대량 포함
- 해외 IP + 대량 응답 조합
- 정상 응답처럼 보이지만 민감 필드가 과도하게 반환되는 패턴
7.2 시나리오 기반 그룹화
- “해외 IP + 반복 조회 + 대용량 응답 + 동일 API”
- “정상 로그인 없음 + 내부용 API 패턴 + 개인정보 필드 다량 반환”
- “장기간 저속 조회 + 동일 구조 응답 반복”
이런 조합은
단일 알람보다 인시던트 단위로 묶어 보는 것이 더 중요합니다.
7.3 사고 후 포렌식
- 최초 유출 시점 추정
- 유출 범위 추정
- 필드 단위 영향도 분석
- 타임라인 자동 생성
여기서 중요한 것은
PLURA-XDR 자체보다도
이런 종류의 데이터 중심 탐지 구조가 필요하다는 점입니다.
8. 정리: 쿠팡 사건이 남긴 가장 큰 교훈
이번 사건이 사실이라면,
핵심은 다음 세 가지로 요약할 수 있습니다.
- 서버 인증·인가 설계 취약점
- 내부자 또는 내부 지식 악용 가능성
- 본문 기반 유출 탐지 부재
이 세 가지가 결합되면
“정상적인 200 OK 응답” 속에서
수천만 건의 개인정보가 장기간 무감지로 유출될 수 있다는 점이 드러납니다.
즉, 이제 보안 전략은
단순히 “막는 것”에서 그치지 않고,
데이터가 어떻게 사용되고 반환되는지를 감시하는 것까지 확장되어야 합니다.
9. 최종 제언
이번 사건이 우리에게 주는 메시지는 분명합니다.
- 보안의 중심은 더 이상 네트워크 경계만이 아닙니다.
- 로그인 성공/실패 여부만 보는 것도 충분하지 않습니다.
- 정상 응답처럼 보이는 데이터 유출까지 봐야 합니다.
따라서 앞으로는 다음 방향이 필요합니다.
조직이 해야 할 것
- API 인증·인가 구조 전수 점검
- 내부용 API 외부 노출 검증
- 마스터 권한·토큰 관리 강화
- 요청/응답 본문 기반 데이터 유출 모니터링 도입
- 저속 장기 조회형 공격 시나리오 탐지 체계 마련
보안 기술이 해야 할 것
- 본문 기반 민감정보 식별
- 시나리오 기반 대량 조회 그룹화
- 필드 단위 포렌식
- 웹/API 이벤트와 계정·호스트 이벤트의 결합 분석
결국 이번 사건은
“정상 로그인 없이 데이터가 빠져나갈 수 있는 구조”를 막지 못하면
대규모 유출은 생각보다 조용하고 오래 지속될 수 있다는 사실을 보여 줍니다.
그래서 이제는
경계 보안 중심에서, 데이터 사용과 응답을 이해하는 보안으로 이동해야 합니다.
용어 정리
IDOR (Insecure Direct Object Reference)
사용자가 직접 조작 가능한 객체 식별자(userId, fileId 등)에 대해
적절한 인증·권한 검증 없이
다른 사용자의 객체에 접근할 수 있게 되는 취약점입니다.
📚 참고하기
- AI 보조 WAF 우회: 공격 자동화 시나리오
- Gartner 하이프 사이클로 본 SIEM과 SOAR – 왜 둘 다 한계가 있는가?
- 우리나라 해킹은 정부의 인증 제도 때문이다
- ISMS 인증제도, 왜 지금은 더 이상 유효하지 않은가?
- 롯데카드 해킹 사고 분석 - 왜 웹방화벽은 무용지물이 되었을까
- SKT 해킹 가설: 유심 데이터 탈취와 BPFDoor 설치, 어떻게 이뤄졌나?