ソブリンAI、データ主権、そしてGDPR: ガラパゴスを超えて
By PLURA
🌐 ソブリンAIは「国産AI」だけを意味しない
最近、国内で議論されているソブリンAI(Sovereign AI)は「国内で開発されたAI」または「外国産AIを排除した国産AI」と誤解されています。
しかし、これはガラパゴス化した閉鎖的エコシステムを作る危険があり、本来の概念とはかけ離れています。
ソブリンAIはAI開発の国籍の問題ではなく、データ主権(Data Sovereignty)から始まります。
つまり、AIが学習・運用するデータの統制権を誰が持つのかが核心です。 🔑
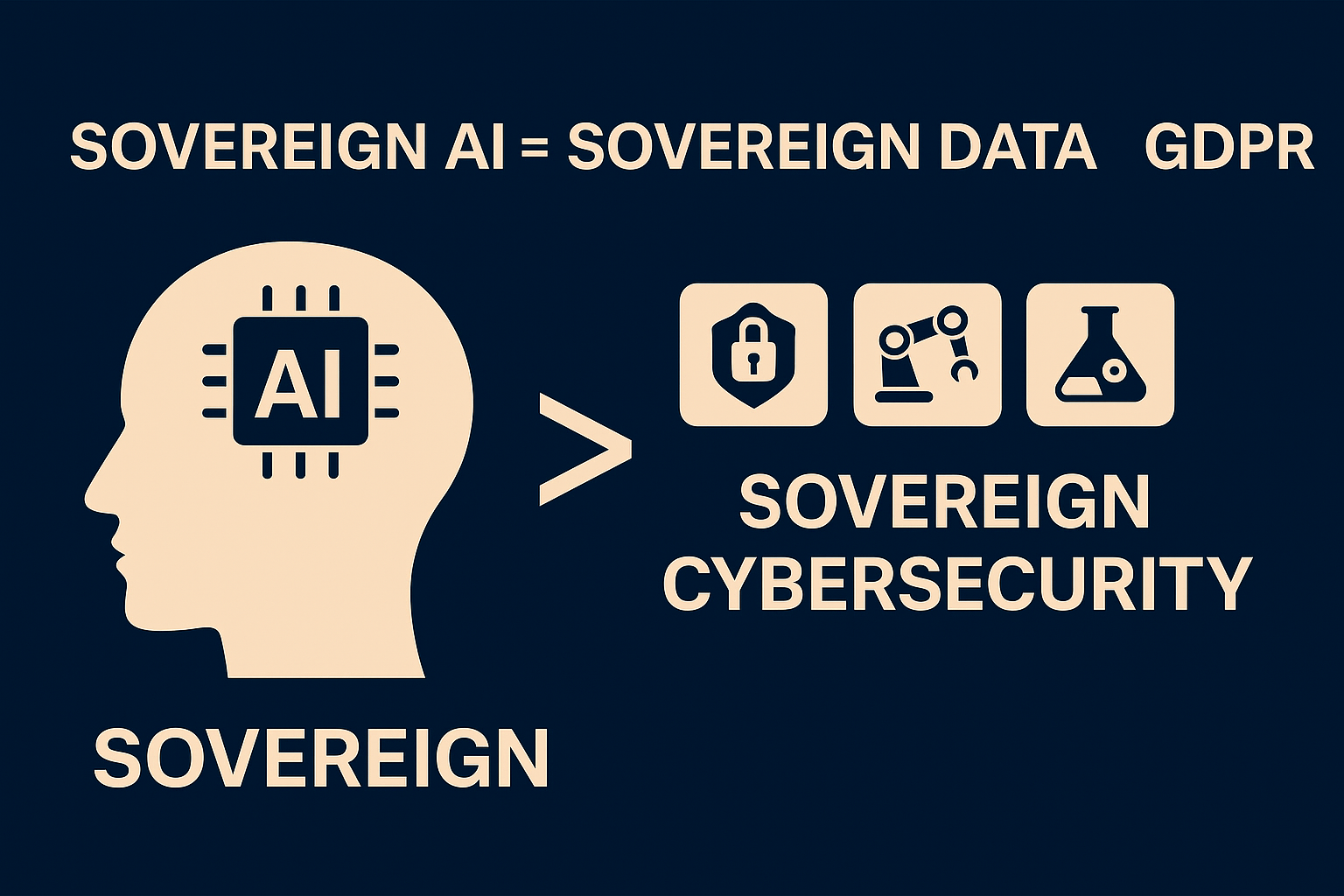
📊 ソブリンAI – ソブリンDATA – GDPRのつながり
| 区分 | ソブリンAI | ソブリンDATA | GDPR (EU) |
|---|---|---|---|
| 核心概念 | 自国/地域内での独立的なAI開発・運用 | データは国家・個人の主権的資産 | 個人情報保護およびデータ主権の保障 |
| 主要目的 | 外国技術依存防止、安全保障・産業競争力確保 | データ統制権確保、国境を越えた移動規制 | プライバシーとデータ権利の保護 |
| 適用範囲 | AIモデル、インフラ、運用規制 | データ収集・保存・処理・移転の全過程 | EU内の個人情報および域外移転 |
| 代表事例 | EU AI Act、各国のSovereign Cloud | 国産クラウド、データローカライゼーション政策 | GDPR (2018)、Schrems II判決 |
| 相互関係 | AI主権はデータ主権の上にのみ成立 | AI学習・推論の原材料かつ基盤 | ソブリンDATAの制度的フレームワーク |
🔒 なぜデータ主権が重要なのか?
-
AIの原材料はデータ
- GPT、Claude、GeminiなどすべてのAIは、大規模データを通じて訓練されます。
- データを制御できない場合、AI主権は空論にすぎません。
-
法的リスク
- Schrems II判決により、米国へのデータ移転はGDPRに違反する可能性が高いと判断されました。
- これは単にEUの問題ではなく、韓国企業が米国クラウドを使う場合も同様に適用され得ます。
-
産業・安保リスク
- 医療・金融・公共データが国外クラウドに流出する場合、その国家は核心資産を失います。
- AIの支配権が外部に依存することは、国家安全保障に直結します。
🚫 誤った解釈: 「国内AI開発 = ソブリンAI」?
一部ではソブリンAIを 国内企業が作ったAI に限定しようとしています。
しかし、これは誤った主張です。
- 国産AIのみを許可すれば、グローバルAIエコシステムから切り離され競争力が弱まります。
- データ主権を確保せずに国産AIだけを強調すると、セキュリティ・倫理・法的基準のないAI を量産することになります。
- それは最終的に「ガラパゴスAI」を作る道になります。
✅ 正しい方向: データ主権に基づくAI戦略
したがって韓国がソブリンAIを推進するなら、次のような戦略が必要です:
- データ主権の強化: GDPRのようにデータ移転・活用を国内規範に合わせる仕組みの整備。
- AIの信頼性確保: データ品質・セキュリティ・倫理原則を満たしたAIのみを公共・産業分野で活用。
- グローバル連携: 閉鎖的な国産化ではなく、グローバルなオープンソース・商用AIも データ主権を前提に活用。
🧩 結論: ソブリンAI → ソブリン・サイバーセキュリティへ
ソブリンAIとは 国内産AI開発 ではなく、
データ主権 (Data Sovereignty) と直結した 国家的規範・安全保障戦略 です。
- ソブリンAI = ソブリンDATA = GDPR的規律
- データ主権なしにAI主権は成立しない
- 国産化論理よりも データ統制・保護体制 が優先
👉 そしてここで止まってはいけません。
AI主権はすなわち サイバーセキュリティ主権 と結びついています。
データが安全でなければ、AIも国家安全保障も守れないからです。
つまり、ソブリンAI → ソブリンデータ → ソブリン・サイバーセキュリティ という拡張されたフレームが必要です。